
September 28, 2017 / by /
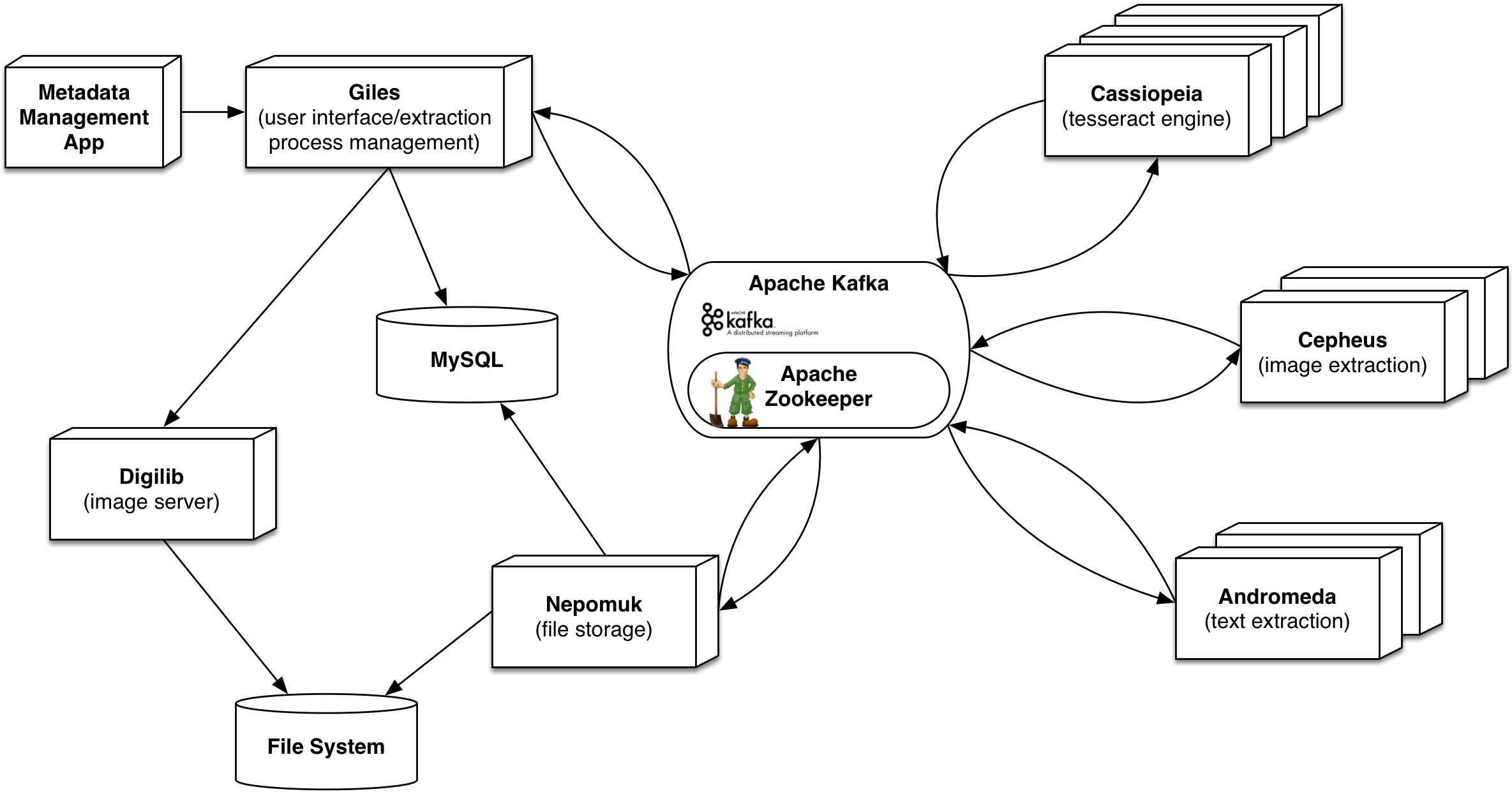
The Giles Ecosystem – Storage, Text Extraction, and OCR of Documents
SEPTEMBER 28, 2017 — Check out our new paper
Damerow, J., Peirson, B.R.E. & Laubichler, M.D., (2017). The Giles Ecosystem – Storage, Text Extraction, and OCR of Documents. Journal of Open Research Software. 5(1), p.26. DOI: http://doi.org/10.5334/jors.164
Abstract
“In the digital humanities, there is a constant need to turn images and PDF files into plain text to apply analyses such as topic modelling, named entity recognition, and other techniques. However, although there exist different solutions to extract text embedded in PDF files or run OCR on images, they typically require additional training (for example, scholars have to learn how to use the command line) or are difficult to automate without programming skills. The Giles Ecosystem is a distributed system based on Apache Kafka that allows users to upload documents for text and image extraction. The system components are implemented using Java and the Spring Framework and are available under an Open Source license on GitHub.”